P1]
In the intricate world of data warehousing and business intelligence, the dimension table stands as a fundamental building block, providing context and descriptive attributes to the raw, numerical data stored in fact tables. Without dimension tables, data would be just a collection of numbers, devoid of meaning and incapable of answering the crucial "who, what, where, when, why, and how" questions that drive business decisions. This article delves deep into the world of dimension tables, exploring their purpose, structure, types, design considerations, and best practices.
Understanding the Role of Dimension Tables
At its core, a dimension table is a collection of descriptive attributes that categorize and contextualize the quantitative measures stored in a fact table. Think of the fact table as holding the "what happened" data – sales figures, website visits, or inventory levels. The dimension table, on the other hand, provides the "who, what, where, when, why, and how" that gives these numbers meaning.
For instance, a fact table recording sales transactions might contain information about the sale amount, the date, and the product ID. Without dimension tables, we would only know the individual sales figures. However, by linking the fact table to dimension tables like Product, Customer, Date, and Store, we can analyze:
- Product: Which products are selling best? Which categories are underperforming?
- Customer: Which customer segments are most valuable? What are their buying patterns?
- Date: What are the seasonal trends in sales? How do sales compare year-over-year?
- Store: Which stores are driving the most revenue? Are there regional variations in performance?
This ability to slice and dice data along different dimensions is what makes data warehousing so powerful for business intelligence. Dimension tables transform raw data into actionable insights.
Structure and Components of a Dimension Table
A typical dimension table consists of several key components:
- Primary Key: A unique identifier for each row in the dimension table. This key is used to establish relationships with the fact table. Often, this is a surrogate key (discussed later).
- Descriptive Attributes: These are the characteristics or properties that describe the dimension. These attributes are the core of the dimension table and allow for filtering, grouping, and reporting. Examples include product name, customer address, date, and store location.
- Surrogate Key: A unique, sequentially generated integer value that serves as the primary key for the dimension table. Surrogate keys are preferred over natural keys (which are derived from the source system) for several reasons, including performance, stability, and handling of changes in the source system.
- Natural Key (Business Key): The unique identifier for the dimension in the source system. This is often included in the dimension table for reference and debugging purposes, but it’s not used as the primary key.
- Hierarchy Attributes: These attributes define hierarchical relationships within the dimension. For example, in a Product dimension, a hierarchy might be Category > Subcategory > Product Name. These hierarchies allow users to drill down and roll up data in reports and dashboards.
- Slowly Changing Dimension (SCD) Attributes: Attributes that may change over time. These attributes require special handling to maintain historical accuracy.
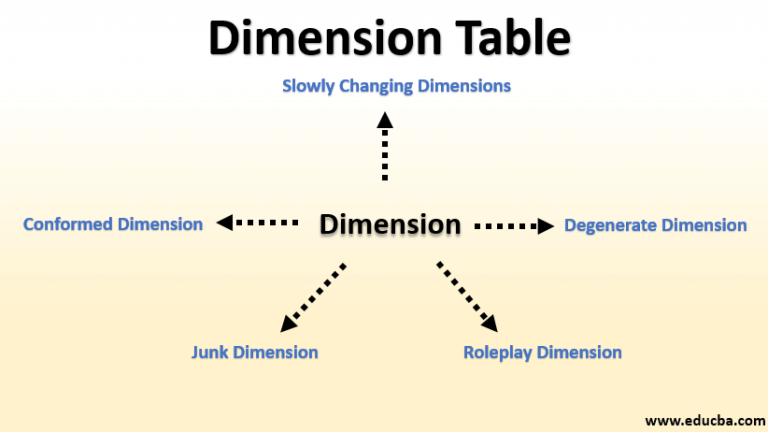
Types of Dimension Tables
Dimension tables can be categorized based on their characteristics and how they are designed to handle changing data:
- Conformed Dimensions: These are dimensions that are shared across multiple fact tables in a data warehouse. Conformed dimensions ensure consistency and comparability of data across different business areas. For example, a Date dimension should be conformed so that sales data and marketing data can be analyzed consistently over time.
- Degenerate Dimensions: These are dimensions that are stored directly in the fact table. They usually represent transactional information that doesn’t warrant its own separate dimension table. A common example is an invoice number or order number.
- Junk Dimensions: These are dimensions that group together several low-cardinality attributes that are frequently used together in queries. This can improve query performance by reducing the number of joins required. For example, a Transaction Status dimension might combine attributes like "Payment Method," "Shipping Method," and "Discount Applied."
- Role-Playing Dimensions: A single physical dimension table can be used in multiple roles within a fact table. For instance, a Date dimension could be used to represent the order date, the ship date, and the delivery date in a sales fact table. Each role will have a separate foreign key relationship to the Date dimension.
- Slowly Changing Dimensions (SCDs): These are the most important type of dimension table when dealing with historical data. They are designed to handle changes to dimension attributes over time. Different types of SCDs exist, each with its own approach to managing change.
Understanding Slowly Changing Dimensions (SCDs)
Slowly Changing Dimensions (SCDs) are crucial for maintaining historical accuracy in a data warehouse. Since dimension attributes can change over time (e.g., a customer’s address, a product’s price), SCDs provide mechanisms to track these changes. The most common SCD types are:
- Type 0 (Retain Original): The dimension attribute is never changed. This is suitable for attributes that are considered fixed or historical, such as a product’s original manufacturing date.
- Type 1 (Overwrite): The old value of the attribute is overwritten with the new value. This is the simplest approach, but it results in a loss of historical information. It’s suitable for attributes where historical accuracy is not important.
- Type 2 (Add New Row): A new row is added to the dimension table with the new attribute value and a new surrogate key. The old row is marked as inactive, typically with start and end dates. This approach preserves the full history of changes and allows for accurate reporting on past states. It is the most common SCD type.
- Type 3 (Add New Column): A new column is added to the dimension table to store the new attribute value. This approach is less flexible than Type 2, as it requires schema changes when new attributes are added. It’s suitable for tracking a limited number of changes to specific attributes.
- Type 4 (Add History Table): A separate history table is created to store changes to the dimension attributes. This approach is more complex but can be useful for handling complex historical requirements.
- Type 6 (Combination of Type 1, Type 2, and Type 3): Combines elements of different SCD types. For example, you might overwrite some attributes (Type 1) while creating new rows for others (Type 2).
The choice of SCD type depends on the specific business requirements and the importance of historical accuracy for each attribute.
Design Considerations and Best Practices
Designing effective dimension tables requires careful consideration of several factors:
- Granularity: Determine the appropriate level of detail for each dimension. Too granular, and the dimension table becomes unwieldy and difficult to manage. Too coarse, and you lose the ability to drill down and analyze data at the desired level of detail.
- Data Quality: Ensure the accuracy and consistency of the data in the dimension tables. Inaccurate or inconsistent data can lead to misleading reports and poor business decisions.
- Performance: Optimize the dimension tables for query performance. This includes choosing appropriate data types, creating indexes, and partitioning large tables.
- Maintainability: Design the dimension tables to be easily maintained and updated. This includes using surrogate keys, automating data loading processes, and implementing proper data governance policies.
- Data Modeling: Use a star schema or snowflake schema for the data warehouse. These schemas are designed to optimize query performance and simplify data analysis.
- Documentation: Document the structure and purpose of each dimension table. This makes it easier for users to understand and use the data.
Benefits of Well-Designed Dimension Tables
Well-designed dimension tables offer numerous benefits:
- Improved Data Analysis: Provide context and descriptive attributes that enable users to analyze data in meaningful ways.
- Enhanced Business Intelligence: Support the creation of insightful reports and dashboards that drive better business decisions.
- Increased Data Consistency: Ensure consistency and comparability of data across different business areas.
- Simplified Data Integration: Facilitate the integration of data from multiple source systems.
- Improved Query Performance: Optimize query performance by reducing the number of joins required.
Conclusion
Dimension tables are the unsung heroes of data warehousing. They provide the context and descriptive attributes that transform raw data into actionable insights. By understanding the different types of dimension tables, the importance of SCDs, and the best practices for design, organizations can build robust and effective data warehouses that drive better business decisions. Investing in well-designed dimension tables is an investment in the long-term success of any data-driven organization.
Frequently Asked Questions (FAQ)
Q: What is the difference between a fact table and a dimension table?
A: A fact table contains quantitative data (measures) and foreign keys that reference dimension tables. Dimension tables contain descriptive attributes that provide context to the measures in the fact table.
Q: Why use surrogate keys instead of natural keys?
A: Surrogate keys offer several advantages: performance (integer comparisons are faster), stability (natural keys can change in the source system), and independence from the source system.
Q: What is the purpose of Slowly Changing Dimensions (SCDs)?
A: SCDs are used to handle changes to dimension attributes over time while preserving historical accuracy.
Q: Which SCD type is the best?
A: The best SCD type depends on the specific business requirements and the importance of historical accuracy for each attribute. Type 2 is the most common and generally recommended for attributes where historical tracking is important.
Q: What are conformed dimensions?
A: Conformed dimensions are dimensions that are shared across multiple fact tables, ensuring consistency and comparability of data across different business areas.
Q: What is a degenerate dimension?
A: A degenerate dimension is a dimension that is stored directly in the fact table, typically representing transactional information that doesn’t warrant its own separate dimension table.
Q: How do I choose the right granularity for a dimension table?
A: Consider the level of detail required for analysis and reporting. The granularity should be fine enough to support the necessary analysis but not so fine that the dimension table becomes unwieldy.
Q: What are some common mistakes to avoid when designing dimension tables?
A: Common mistakes include using natural keys as primary keys, neglecting SCDs, poor data quality, and inadequate documentation.
Q: What is a star schema and a snowflake schema?
A: A star schema is a data warehouse schema where a fact table is surrounded by dimension tables. A snowflake schema is a variation of the star schema where some dimension tables are normalized, resulting in a more complex structure.
Q: How important is data quality in dimension tables?
A: Data quality is crucial. Inaccurate or inconsistent data in dimension tables can lead to misleading reports and poor business decisions. Implement data quality checks and cleansing processes to ensure data accuracy.
Leave a Reply