P1]
In the modern data-driven world, databases are the backbone of countless applications, from e-commerce platforms to social media networks. These databases store vast amounts of information, and efficiently retrieving that information is crucial for a positive user experience and optimal system performance. This is where database indexing comes into play. Think of it as the index in a textbook, guiding you directly to the relevant information instead of forcing you to read the entire book.
This article delves into the world of database indexing, exploring its purpose, types, implementation, performance considerations, and best practices.
What is Database Indexing?
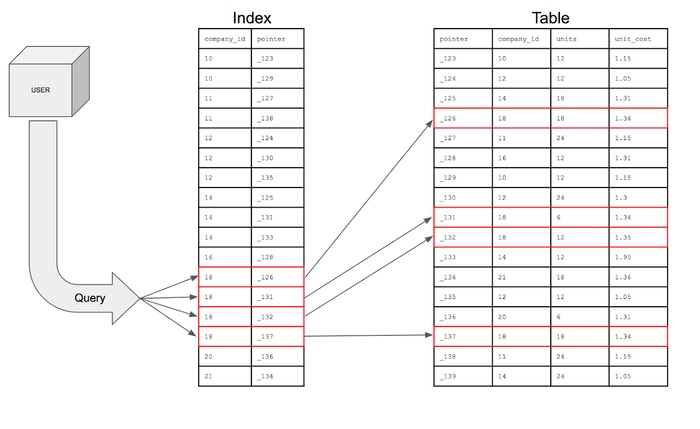
Database indexing is a data structure technique used to improve the speed of data retrieval operations on a database table. An index is essentially a sorted copy of a subset of columns in a table, along with pointers (or row IDs) to the corresponding rows in the original table. Instead of scanning the entire table row by row (a full table scan), the database engine can use the index to quickly locate the specific rows that match a query’s criteria.
Imagine searching for a specific book in a library. Without a catalog (the index), you would have to browse every shelf, one by one. With a catalog, you can quickly find the book’s location based on its title, author, or subject.
Why Use Database Indexing?
The primary reason for using database indexing is to improve query performance. Here’s a breakdown of the benefits:
- Faster Data Retrieval: Indexes drastically reduce the time it takes to retrieve data, especially for queries involving
WHEREclauses,ORDER BYclauses, and joins. - Improved Application Performance: Faster query execution translates to faster response times for applications, leading to a better user experience.
- Reduced I/O Operations: Indexes minimize the number of disk I/O operations required to find data, as the database engine only needs to read the relevant index pages and the corresponding table rows.
- Enhanced Scalability: As your database grows, indexing becomes even more crucial for maintaining performance. Indexes help the database handle increasing data volumes and query loads.

Types of Database Indexes:
There are several types of database indexes, each with its own characteristics and suitability for different scenarios. Here are some of the most common:

B-Tree Index: This is the most widely used index type. B-trees are balanced tree structures that allow for efficient searching, insertion, and deletion of data. They are well-suited for range queries (e.g., finding all products with a price between $10 and $20) and equality searches (e.g., finding a user with a specific ID). Most database systems default to B-tree indexes when no specific index type is specified.

Hash Index: Hash indexes use a hash function to map column values to a specific location in the index. They are extremely fast for equality searches (e.g., finding a record with a specific primary key). However, they are not suitable for range queries or sorting. Hash indexes are less commonly used than B-tree indexes.
Bitmap Index: Bitmap indexes are particularly effective for columns with low cardinality (i.e., a small number of distinct values, such as gender, marital status, or product category). They use a bitmap to represent the presence or absence of each value in the column. Bitmap indexes can be very efficient for complex queries involving multiple
ANDandORconditions.Full-Text Index: Full-text indexes are designed for searching text-based data, such as articles, blog posts, or product descriptions. They allow you to perform searches using keywords, phrases, and other text-related criteria. These indexes typically involve tokenization (breaking down text into individual words), stemming (reducing words to their root form), and stop word removal (eliminating common words like "the," "a," and "is").
Spatial Index: Spatial indexes are used to efficiently query and analyze geographic data, such as points, lines, and polygons. They are commonly used in applications involving mapping, location-based services, and geographic information systems (GIS).
Clustered Index: A clustered index determines the physical order in which data is stored in the table. There can only be one clustered index per table. Typically, the primary key is used as the clustered index. When a table has a clustered index, the data rows are physically sorted based on the index key. This makes range queries and sequential access very efficient.
Non-Clustered Index: A non-clustered index is a separate structure that contains a copy of the indexed columns and pointers to the corresponding rows in the table. A table can have multiple non-clustered indexes. Non-clustered indexes provide faster access to specific data without affecting the physical order of the table.

Implementing Database Indexes:
Creating indexes is typically a straightforward process, using SQL commands:
-- Create a B-tree index on the 'email' column of the 'users' table
CREATE INDEX idx_users_email ON users (email);
-- Create a composite index on the 'last_name' and 'first_name' columns
CREATE INDEX idx_users_name ON users (last_name, first_name);
-- Create a unique index on the 'username' column
CREATE UNIQUE INDEX idx_users_username ON users (username);
-- Create a full-text index on the 'description' column of the 'products' table (syntax varies by database system)
CREATE FULLTEXT INDEX idx_products_description ON products (description);It’s crucial to choose the appropriate columns to index based on the queries that are frequently executed. Analyzing query patterns and using database monitoring tools can help identify the best candidates for indexing.
Performance Considerations:
While indexes can significantly improve query performance, they also come with certain overheads:
- Storage Space: Indexes require additional storage space, as they are essentially copies of data.
- Write Performance: When data is inserted, updated, or deleted, the indexes must also be updated, which can impact write performance.
- Index Maintenance: Indexes may need to be rebuilt or reorganized periodically to maintain their efficiency, especially after a large number of data modifications.
It’s essential to strike a balance between read and write performance when designing indexes. Over-indexing can negatively impact write performance without providing significant benefits to read performance.
Best Practices for Database Indexing:
- Index Frequently Queried Columns: Focus on indexing columns that are commonly used in
WHEREclauses,ORDER BYclauses, and join conditions. - Use Composite Indexes: For queries that involve multiple columns in the
WHEREclause, consider creating a composite index that includes all of those columns. The order of columns in a composite index matters. Generally, the most selective column (the one with the most distinct values) should come first. - Index Foreign Keys: Indexing foreign key columns can significantly improve the performance of join operations.
- Avoid Indexing Columns with Low Cardinality: Indexing columns with very few distinct values (e.g., a boolean column) may not provide significant benefits and can even degrade performance. Bitmap indexes can be an exception to this rule.
- Monitor and Analyze Query Performance: Use database monitoring tools to identify slow-running queries and determine if indexing can help.
- Regularly Rebuild or Reorganize Indexes: Over time, indexes can become fragmented, which can negatively impact performance. Regularly rebuilding or reorganizing indexes can help maintain their efficiency.
- Consider the Trade-offs: Carefully consider the trade-offs between read and write performance when designing indexes. Over-indexing can negatively impact write performance.
- Use the Right Index Type: Choose the index type that is most appropriate for the type of queries you are running.
- Test and Validate: After creating or modifying indexes, test and validate the performance impact to ensure that the changes are actually improving query performance.
FAQ:
Q: How many indexes should I create on a table?
- A: There is no magic number. The optimal number of indexes depends on the specific queries that are executed against the table, the size of the table, and the frequency of data modifications. It’s important to monitor query performance and adjust the indexes accordingly.
Q: Does the order of columns in a composite index matter?
- A: Yes, the order of columns in a composite index can significantly impact performance. Generally, the most selective column (the one with the most distinct values) should come first.
Q: When should I rebuild or reorganize indexes?
- A: Indexes should be rebuilt or reorganized when they become fragmented, which can happen after a large number of data modifications. The frequency of rebuilding or reorganizing indexes depends on the specific database system and the workload.
Q: Can indexes slow down write operations?
- A: Yes, indexes can slow down write operations (inserts, updates, and deletes) because the indexes must also be updated whenever the data in the table changes.
Q: Are indexes automatically created by the database system?
- A: Most database systems automatically create an index on the primary key column. However, you typically need to manually create indexes on other columns that are frequently queried.
Conclusion:
Database indexing is a powerful technique for improving query performance and enhancing the overall efficiency of database applications. By understanding the different types of indexes, their performance characteristics, and best practices for implementation, you can effectively leverage indexing to optimize your database and deliver a faster, more responsive user experience. Remember to continuously monitor and analyze query performance to identify opportunities for further optimization and ensure that your indexes remain effective over time. The art and science of database indexing lies in finding the right balance between read and write performance, and tailoring your indexing strategy to the specific needs of your application.
Leave a Reply