P1]
In the ever-evolving landscape of data management, organizations are constantly seeking efficient methods to ingest and process vast amounts of information. One technique that stands out for its ability to handle large datasets effectively and minimize resource consumption is incremental load. This article provides a comprehensive overview of incremental load, exploring its principles, benefits, challenges, implementation strategies, and real-world applications.
What is Incremental Load?
Incremental load, also known as delta load, is a data integration technique that focuses on loading only the new or modified data from a source system into a target system. Instead of performing a full load, which involves transferring the entire dataset every time, incremental load identifies and extracts only the changes made since the last load, drastically reducing the amount of data processed.
Think of it like updating a library catalog. Instead of re-cataloging every book in the library each day, you only add the new books and update the records of books that have been borrowed, returned, or had their information changed.
Why Use Incremental Load?
The primary motivation for using incremental load is to improve efficiency and performance in data integration processes. Here are some key benefits:
- Reduced Load Time: By processing only the changes, incremental load significantly reduces the time required to load data into the target system. This is crucial for systems that require near real-time data updates.
- Lower Resource Consumption: Less data transfer translates to lower bandwidth usage, reduced storage requirements, and less processing power needed. This leads to cost savings and improved system performance.
- Minimized Impact on Source Systems: Full loads can put a significant strain on source systems, especially during peak hours. Incremental load minimizes this impact by extracting only a small portion of the data.
- Improved Data Freshness: Incremental load enables more frequent data updates, ensuring that the target system contains the most up-to-date information. This is critical for decision-making processes that rely on real-time insights.
- Enhanced Scalability: As data volumes grow, incremental load becomes increasingly important for maintaining efficient data integration processes. It allows systems to scale more effectively without experiencing performance bottlenecks.
- Simplified Error Handling: Dealing with smaller data sets in incremental loads can simplify error identification and correction compared to the complexities of managing errors in full loads.
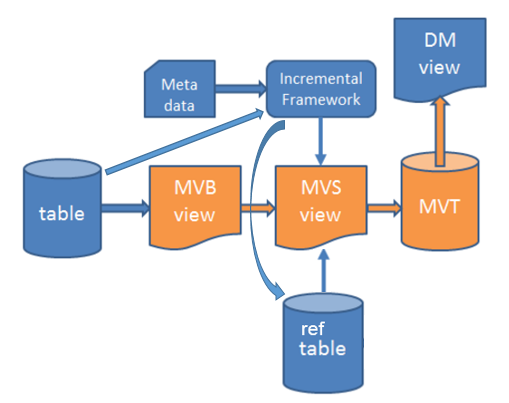
Principles of Incremental Load:

The success of incremental load relies on several key principles:
- Change Data Capture (CDC): Identifying the changes that have occurred in the source system since the last load is crucial. CDC mechanisms are used to track these changes and make them available for extraction.
- Data Extraction: Extracting only the changed data from the source system. This involves querying the CDC mechanisms or using other techniques to identify and retrieve the relevant records.
- Data Transformation: Transforming the extracted data into a format that is compatible with the target system. This may involve data cleansing, data mapping, and data aggregation.
- Data Loading: Loading the transformed data into the target system. This may involve inserting new records, updating existing records, or deleting records.
- Maintaining State: Tracking the last successful load time or a unique identifier to ensure that only new or modified data is processed in subsequent loads. This helps prevent data duplication or loss.

Change Data Capture (CDC) Techniques:
CDC is the cornerstone of incremental load. Several techniques are used to capture changes in source systems:
- Timestamps: This is the simplest approach, relying on a timestamp column in the source table to identify records that have been created or modified since the last load. It requires the source system to accurately maintain timestamp information.
- Version Numbers: Similar to timestamps, version numbers track changes to records. Each time a record is updated, its version number is incremented.
- Triggers: Database triggers are stored procedures that are automatically executed when specific events occur, such as inserting, updating, or deleting records. Triggers can be used to capture changes and store them in a separate change table.
- Log-Based CDC: This technique involves reading the transaction logs of the source database to identify changes. It is a more reliable and efficient approach than triggers, as it does not require modifications to the source database schema.
- Snapshot Comparison: This involves taking periodic snapshots of the source data and comparing them to identify changes. This approach is less efficient than other methods, especially for large datasets.
Implementation Strategies:
Implementing incremental load requires careful planning and execution. Here are some common strategies:
- ETL Tools: Many commercial and open-source ETL (Extract, Transform, Load) tools provide built-in support for incremental load. These tools often include CDC mechanisms and data transformation capabilities.
- Custom Scripting: Incremental load can also be implemented using custom scripts written in languages like Python, Java, or SQL. This approach offers more flexibility but requires more development effort.
- Data Warehousing Platforms: Modern data warehousing platforms, such as Snowflake, Amazon Redshift, and Google BigQuery, provide features that facilitate incremental load, such as change data capture and data versioning.
- Cloud-Based Data Integration Services: Cloud providers offer data integration services that simplify the implementation of incremental load. These services often provide pre-built connectors for various data sources and targets.
Challenges of Incremental Load:
While incremental load offers numerous benefits, it also presents some challenges:
- Complexity: Implementing incremental load can be more complex than full load, especially when dealing with complex data transformations or multiple source systems.
- Data Quality: Errors in the CDC mechanism or data transformation process can lead to data quality issues in the target system.
- Schema Changes: Changes to the source system schema can break the incremental load process. Careful planning and monitoring are required to handle schema changes effectively.
- Handling Deletes: Properly handling deleted records in the source system is crucial to maintain data integrity in the target system.
- Initial Load: An initial full load is typically required to populate the target system before incremental load can be implemented.
Real-World Applications:
Incremental load is widely used in various industries and applications:
- Data Warehousing: Loading data from operational systems into a data warehouse for reporting and analysis.
- Business Intelligence: Updating dashboards and reports with the latest data.
- Customer Relationship Management (CRM): Synchronizing customer data between different systems.
- E-commerce: Updating product catalogs and order information.
- Financial Services: Tracking transactions and updating account balances.
- IoT (Internet of Things): Processing sensor data in near real-time.
FAQ:
Q: When should I use incremental load?
- A: Use incremental load when you have large datasets, frequent data updates, and limited resources. It’s particularly beneficial when full loads are impractical or too resource-intensive.
Q: What is the difference between full load and incremental load?
- A: Full load involves transferring the entire dataset from the source to the target system each time. Incremental load only transfers the new or modified data.
Q: How do I choose the right CDC technique?
- A: The choice of CDC technique depends on the capabilities of the source system, the volume of data, and the desired level of accuracy. Log-based CDC is generally the most reliable and efficient approach, but it may not be supported by all source systems.
Q: What are the common errors in incremental load?
- A: Common errors include data duplication, data loss, incorrect data transformations, and failures in the CDC mechanism.
Q: How do I handle schema changes in incremental load?
- A: Schema changes require careful planning and coordination. You may need to update the data transformation process and the CDC mechanism to accommodate the changes.
Q: What is a "late arriving dimension" and how does incremental loading address it?
- A: A late arriving dimension refers to a situation where a dimension record (e.g., customer details) arrives in the data warehouse after the fact record (e.g., order details). Incremental loading, especially when combined with techniques like slowly changing dimensions (SCDs), allows you to update the dimension table with the late arriving information without needing to reprocess the entire fact table. You can identify the late arriving record through CDC, and then update the relevant dimension table record accordingly.
Q: Can I use incremental load with unstructured data?
- A: Yes, but it’s more complex. You need to define a mechanism to identify changes in the unstructured data. This might involve using hashing algorithms to detect modifications to files or using metadata to track changes.
Q: How do I ensure data quality in incremental load?
- A: Implement data quality checks at various stages of the incremental load process, including data extraction, transformation, and loading. Use data profiling tools to identify data quality issues and implement data cleansing rules to correct them.
Q: What are the security considerations for incremental load?
- A: Ensure that data is encrypted during transit and at rest. Implement access controls to restrict access to sensitive data. Regularly audit the incremental load process to identify and address security vulnerabilities.
Conclusion:
Incremental load is a powerful technique for efficiently integrating data from various sources into a target system. By focusing on only the changes, it reduces load time, lowers resource consumption, and improves data freshness. While implementing incremental load can be complex, the benefits it offers in terms of performance, scalability, and cost savings make it a valuable tool for any organization dealing with large volumes of data. Careful planning, a robust CDC mechanism, and a well-defined data transformation process are essential for successful implementation. As data volumes continue to grow, incremental load will become increasingly important for maintaining efficient and effective data integration processes. By understanding the principles, challenges, and implementation strategies outlined in this article, organizations can leverage incremental load to unlock the full potential of their data and gain a competitive advantage.

Leave a Reply