P1]
In today’s data-driven world, organizations rely heavily on data to make informed decisions, optimize processes, and gain a competitive edge. However, raw data is often messy, incomplete, and inconsistent. This is where data cleansing, also known as data scrubbing or data cleaning, comes into play. It’s the critical process of identifying and correcting errors, inconsistencies, and inaccuracies in a dataset to ensure its quality and reliability. Without effective data cleansing, the insights derived from data analysis can be misleading, leading to flawed strategies and potentially costly mistakes.
This article delves into the intricacies of data cleansing, exploring its importance, common techniques, the challenges involved, and the benefits of implementing a robust data cleansing strategy.
Why is Data Cleansing Crucial?
The importance of data cleansing cannot be overstated. Consider these critical reasons why it’s essential:
Improved Decision-Making: Clean data ensures that analyses are based on accurate and reliable information. This leads to better-informed decisions, reduced risks, and improved business outcomes. Imagine a marketing campaign targeting customers based on inaccurate demographic data. The campaign would likely be ineffective and waste valuable resources.
Enhanced Data Quality: Data cleansing improves the overall quality of data by removing errors, inconsistencies, and redundancies. This results in a more consistent and trustworthy dataset that can be used with confidence across different departments and applications.

Increased Efficiency: Clean data simplifies data analysis and reporting processes. Analysts spend less time identifying and correcting errors, allowing them to focus on extracting valuable insights. This translates to increased efficiency and productivity.

Reduced Costs: Dirty data can lead to costly errors and inefficiencies. For example, inaccurate inventory data can result in overstocking or stockouts, leading to financial losses. Data cleansing helps to prevent these errors, saving the organization money.
Compliance with Regulations: Many industries are subject to strict data regulations, such as GDPR (General Data Protection Regulation) and HIPAA (Health Insurance Portability and Accountability Act). Data cleansing helps organizations to comply with these regulations by ensuring that personal data is accurate, complete, and protected.
Better Customer Relationships: Accurate customer data is crucial for providing personalized experiences and building strong customer relationships. Data cleansing ensures that customer information is up-to-date and accurate, enabling organizations to communicate effectively and meet customer needs.
Improved Data Integration: Data cleansing is essential for integrating data from different sources. By standardizing data formats and resolving inconsistencies, data cleansing facilitates seamless data integration and enables organizations to create a unified view of their data.

![]()
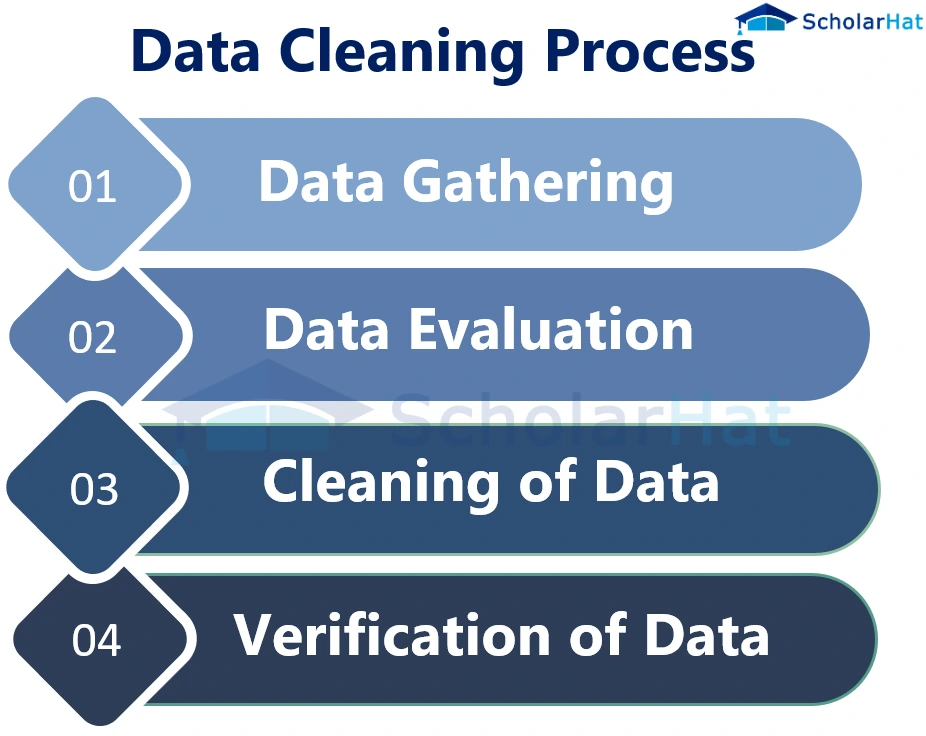
Common Data Cleansing Techniques
Data cleansing involves a range of techniques to identify and correct data errors and inconsistencies. Here are some of the most common methods:
Data Auditing: This involves examining the data to identify potential errors, inconsistencies, and missing values. Data auditing can be performed manually or using automated tools. Techniques include statistical analysis, data profiling, and visual inspection.
Data Standardization: This process involves transforming data into a consistent format. This can include standardizing date formats, address formats, and abbreviations. For example, converting all date entries to the format "YYYY-MM-DD" ensures consistency across the dataset.
Data Transformation: This involves converting data from one format to another. This may be necessary when integrating data from different sources or when preparing data for analysis. For example, converting currency values from different currencies to a single currency.
Data Deduplication: This involves identifying and removing duplicate records from the dataset. This can be a complex process, especially when dealing with large datasets. Deduplication algorithms often rely on fuzzy matching techniques to identify records that are similar but not identical.
Missing Value Handling: This involves addressing missing values in the dataset. There are several techniques for handling missing values, including:
- Deletion: Removing records with missing values. This is a simple approach but can lead to data loss.
- Imputation: Replacing missing values with estimated values. Common imputation techniques include mean imputation, median imputation, and mode imputation.
- Prediction: Using machine learning models to predict missing values based on other variables in the dataset.
Error Correction: This involves correcting errors in the dataset. This can include correcting spelling errors, grammatical errors, and logical errors. Error correction can be performed manually or using automated tools.
Data Enrichment: This involves adding additional information to the dataset to improve its completeness and accuracy. This can include adding demographic data, geographic data, or product information.
Outlier Detection and Removal: Outliers are data points that deviate significantly from the rest of the data. Outliers can be caused by errors in data collection or entry, or they may represent genuine anomalies. Outlier detection techniques include statistical methods, such as Z-score and IQR (Interquartile Range), and machine learning algorithms.
Data Validation: This involves verifying that the data meets certain criteria. This can include checking that data is within a specific range, that data is of a specific type, and that data meets certain business rules.
Challenges in Data Cleansing
While data cleansing is essential, it’s not without its challenges:
Complexity: Data cleansing can be a complex and time-consuming process, especially when dealing with large and diverse datasets.
Scalability: Scaling data cleansing processes to handle large volumes of data can be challenging.
Data Variety: Different data sources may have different data formats, data types, and data quality issues. This makes it difficult to apply a uniform data cleansing strategy.
Subjectivity: Some data cleansing decisions are subjective. For example, determining whether a value is an outlier or whether two records are duplicates may require human judgment.
Maintaining Data Quality: Data quality can degrade over time as new data is added to the dataset. It’s important to implement ongoing data cleansing processes to maintain data quality.
Lack of Resources: Many organizations lack the resources, including skilled personnel and specialized tools, to effectively cleanse their data.
Data Governance: Without clear data governance policies and procedures, data cleansing efforts can be inconsistent and ineffective.
Benefits of a Robust Data Cleansing Strategy
Implementing a robust data cleansing strategy offers numerous benefits to organizations:
- Improved Data Accuracy: Reduces errors and inconsistencies, leading to more accurate data.
- Enhanced Data Consistency: Standardizes data formats and values, creating a more consistent dataset.
- Increased Data Reliability: Increases confidence in the data, making it more reliable for decision-making.
- Better Data Integration: Facilitates seamless data integration from different sources.
- Faster Data Analysis: Reduces the time spent on data preparation, allowing analysts to focus on extracting insights.
- Reduced Costs: Prevents costly errors and inefficiencies caused by dirty data.
- Improved Compliance: Helps organizations to comply with data regulations.
- Enhanced Customer Satisfaction: Improves customer relationships by ensuring accurate and up-to-date customer information.
- Competitive Advantage: Enables organizations to make better-informed decisions and gain a competitive edge.
Implementing a Data Cleansing Strategy
Implementing an effective data cleansing strategy involves the following steps:
- Define Data Quality Goals: Establish clear goals for data quality. What level of accuracy, completeness, and consistency is required?
- Assess Current Data Quality: Evaluate the current state of data quality. Identify the most common data quality issues.
- Develop a Data Cleansing Plan: Create a detailed plan for addressing data quality issues. This plan should include specific techniques, tools, and timelines.
- Select Data Cleansing Tools: Choose the right data cleansing tools for the job. There are many commercial and open-source tools available.
- Implement Data Cleansing Processes: Execute the data cleansing plan. This may involve manual cleansing, automated cleansing, or a combination of both.
- Monitor Data Quality: Continuously monitor data quality to ensure that it meets the defined goals.
- Automate Data Cleansing: Automate data cleansing processes as much as possible to improve efficiency and consistency.
- Establish Data Governance: Implement data governance policies and procedures to ensure that data quality is maintained over time.
- Train Staff: Provide training to staff on data cleansing techniques and best practices.
- Regularly Review and Update: Regularly review and update the data cleansing strategy to ensure that it remains effective.
Data Cleansing Tools
Several data cleansing tools are available in the market, ranging from open-source options to sophisticated commercial solutions. Some popular tools include:
- OpenRefine: A powerful open-source tool for exploring, cleaning, and transforming data.
- Trifacta Wrangler: A commercial data preparation platform that offers a visual interface for data cleansing and transformation.
- Talend Data Integration: A comprehensive data integration platform that includes data cleansing capabilities.
- Informatica Data Quality: A leading data quality platform that provides a range of data cleansing and profiling features.
- SAS Data Management: A data management platform that offers data cleansing, data integration, and data governance capabilities.
Conclusion
Data cleansing is a critical process for ensuring the quality and reliability of data. By implementing a robust data cleansing strategy, organizations can improve decision-making, enhance data quality, increase efficiency, reduce costs, and comply with regulations. While data cleansing can be challenging, the benefits of clean data far outweigh the costs. As organizations continue to rely on data to drive their business strategies, data cleansing will become even more important. Investing in data cleansing is an investment in the future of the organization.
FAQ: Data Cleansing
Q: What is the difference between data cleansing and data integration?
A: Data cleansing focuses on improving the quality of data by correcting errors, inconsistencies, and inaccuracies. Data integration focuses on combining data from different sources into a unified view. While these are distinct processes, they are often performed together. Data cleansing is often a prerequisite for successful data integration.
Q: How often should data cleansing be performed?
A: The frequency of data cleansing depends on the rate at which data changes and the criticality of data quality. For some datasets, data cleansing may need to be performed daily or even hourly. For other datasets, data cleansing may only need to be performed monthly or quarterly. A continuous data quality monitoring system can help determine the optimal frequency.
Q: Can data cleansing be fully automated?
A: While many data cleansing tasks can be automated, some tasks require human judgment. For example, determining whether two records are duplicates may require a human to review the records and make a decision. The goal should be to automate as much of the data cleansing process as possible while still ensuring data quality.
Q: What skills are needed for data cleansing?
A: Data cleansing requires a combination of technical skills and business knowledge. Technical skills include data analysis, data manipulation, and programming. Business knowledge is needed to understand the context of the data and to identify potential errors and inconsistencies.
Q: What are the biggest challenges in data cleansing?
A: The biggest challenges in data cleansing include dealing with large and diverse datasets, scaling data cleansing processes, maintaining data quality over time, and overcoming the lack of resources and data governance.
Q: How do I measure the success of a data cleansing project?
A: The success of a data cleansing project can be measured by tracking key metrics such as data accuracy, data completeness, data consistency, and data reliability. These metrics should be defined before the project begins and tracked throughout the project. Improvements in these metrics indicate the success of the data cleansing project.
Q: What is the role of data governance in data cleansing?
A: Data governance plays a critical role in data cleansing by establishing policies and procedures for managing data quality. Data governance helps to ensure that data cleansing efforts are consistent, effective, and aligned with business goals. A strong data governance framework provides the foundation for a successful data cleansing program.
Leave a Reply