P1]
In today’s data-driven world, organizations are constantly bombarded with information from various sources. This data, often fragmented and inconsistent, holds immense potential for driving business decisions, improving efficiency, and gaining a competitive edge. However, raw data is rarely usable in its unprocessed form. This is where ETL (Extract, Transform, Load) pipelines come into play. ETL is the cornerstone of data warehousing and business intelligence, acting as the crucial bridge between raw data and actionable insights.
This article delves into the intricacies of ETL pipelines, exploring their purpose, components, best practices, and challenges. We’ll cover the key stages of ETL, different architectural approaches, and the tools and technologies used to build and maintain robust data pipelines.
Understanding the Purpose of ETL
At its core, ETL is a process that extracts data from multiple sources, transforms it into a consistent and usable format, and loads it into a target data warehouse or data lake. This process allows organizations to:
- Consolidate Data: Integrate data from disparate sources into a single, unified repository.
- Improve Data Quality: Cleanse, standardize, and validate data to ensure accuracy and consistency.
- Enable Business Intelligence: Provide a reliable and consistent data source for reporting, analysis, and decision-making.
- Enhance Data Governance: Enforce data quality rules and ensure compliance with regulatory requirements.
- Support Data Migration: Migrate data from legacy systems to new platforms.

The Three Pillars of ETL: Extract, Transform, Load
The ETL process is comprised of three distinct stages, each playing a critical role in the overall data pipeline:
1. Extract:
The extraction stage involves retrieving data from various sources. These sources can be incredibly diverse and may include:
- Relational Databases: (e.g., MySQL, PostgreSQL, Oracle, SQL Server)
- NoSQL Databases: (e.g., MongoDB, Cassandra)
- Cloud Storage: (e.g., Amazon S3, Azure Blob Storage, Google Cloud Storage)
- Flat Files: (e.g., CSV, TXT, JSON)
- APIs: (e.g., RESTful APIs, SOAP APIs)
- Streaming Data Sources: (e.g., Apache Kafka, Apache Pulsar)

The extraction process should be designed to minimize the impact on the source systems. Common extraction methods include:
- Full Extraction: Extracting all data from the source system. This is suitable for smaller datasets or initial loads.
- Incremental Extraction: Extracting only the data that has changed since the last extraction. This is more efficient for larger datasets and ongoing updates.
- Change Data Capture (CDC): Capturing changes to data as they occur in the source system. This provides near real-time data updates.
Key Considerations for the Extraction Stage:
- Data Source Connectivity: Establishing reliable connections to all data sources.
- Data Format Compatibility: Handling different data formats and structures.
- Data Volume and Velocity: Optimizing extraction processes for large volumes of data and high-velocity data streams.
- Security and Access Control: Ensuring secure access to data sources and protecting sensitive information.
2. Transform:
The transformation stage is where the magic happens. This is where the extracted data is cleansed, standardized, and transformed into a usable format for the target data warehouse or data lake. Common transformation operations include:
- Data Cleansing: Removing inconsistencies, errors, and duplicates from the data.
- Data Standardization: Converting data to a consistent format, such as date formats, currency codes, and address formats.
- Data Enrichment: Adding additional information to the data from external sources.
- Data Aggregation: Summarizing data to create aggregated views.
- Data Filtering: Removing irrelevant or unwanted data.
- Data Sorting: Ordering data based on specific criteria.
- Data Joining: Combining data from multiple sources based on common keys.
- Data Type Conversion: Converting data from one data type to another.
Key Considerations for the Transformation Stage:
- Data Quality Rules: Defining and enforcing data quality rules to ensure data accuracy and consistency.
- Transformation Logic: Designing and implementing complex transformation logic to meet specific business requirements.
- Performance Optimization: Optimizing transformation processes for large datasets and complex transformations.
- Data Lineage: Tracking the origin and transformations applied to the data.
3. Load:
The load stage involves loading the transformed data into the target data warehouse or data lake. The loading process should be optimized for performance and data integrity. Common loading methods include:
- Full Load: Loading all data into the target system, replacing any existing data.
- Incremental Load: Loading only the changed data into the target system, updating existing data or adding new data.
Key Considerations for the Load Stage:
- Target System Compatibility: Ensuring compatibility between the transformed data and the target system’s schema.
- Performance Optimization: Optimizing loading processes for large datasets and complex data structures.
- Data Integrity: Ensuring data integrity during the loading process.
- Error Handling: Implementing robust error handling mechanisms to handle data loading failures.
ETL Architectures: Choosing the Right Approach
The architecture of an ETL pipeline can vary depending on the specific requirements and constraints of the project. Some common ETL architectures include:
- Batch Processing: Data is extracted, transformed, and loaded in batches, typically on a scheduled basis. This is suitable for scenarios where near real-time data updates are not required.
- Real-Time Processing: Data is extracted, transformed, and loaded in real-time or near real-time, allowing for immediate insights. This is suitable for scenarios where timely data is critical, such as fraud detection or real-time analytics.
- Cloud-Based ETL: ETL processes are executed in the cloud, leveraging the scalability and cost-effectiveness of cloud computing. This is increasingly popular as organizations migrate their data and applications to the cloud.
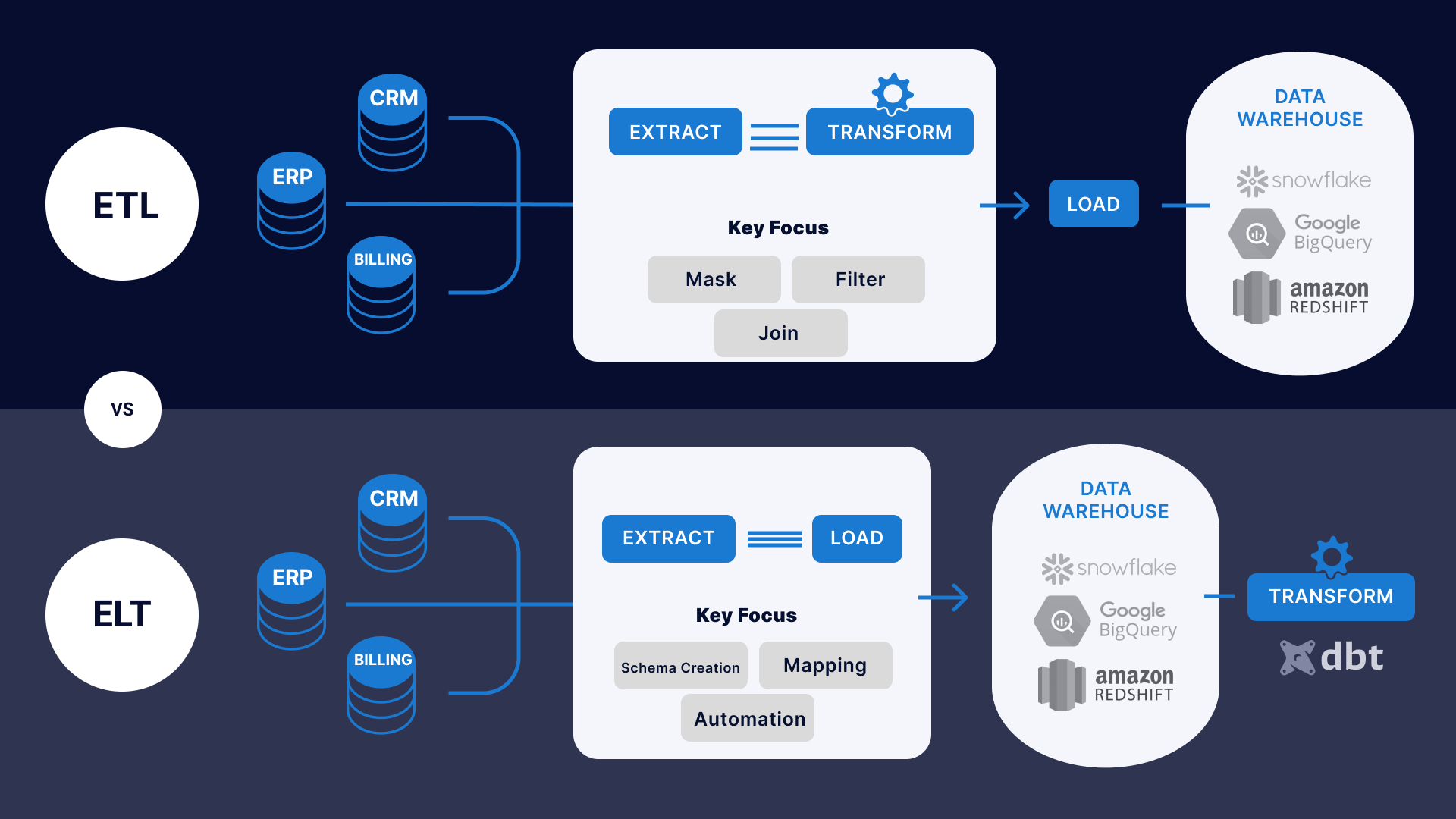
- ELT (Extract, Load, Transform): Data is extracted and loaded into the target system before being transformed. This approach leverages the processing power of the target system for transformations. ELT is particularly suitable for large datasets and cloud-based data warehouses.
Tools and Technologies for Building ETL Pipelines
A wide range of tools and technologies are available for building ETL pipelines, each with its own strengths and weaknesses. Some popular options include:
- Commercial ETL Tools: (e.g., Informatica PowerCenter, IBM DataStage, Oracle Data Integrator) These tools provide a comprehensive suite of features for building and managing ETL pipelines.
- Open-Source ETL Tools: (e.g., Apache NiFi, Apache Kafka Connect, Talend Open Studio) These tools offer a cost-effective alternative to commercial ETL tools.
- Cloud-Based ETL Services: (e.g., AWS Glue, Azure Data Factory, Google Cloud Dataflow) These services provide a fully managed ETL platform in the cloud.
- Programming Languages: (e.g., Python, Java, Scala) These languages can be used to build custom ETL pipelines using libraries and frameworks like Apache Spark and Pandas.
- Data Warehousing Platforms: (e.g., Snowflake, Amazon Redshift, Google BigQuery) These platforms provide built-in ETL capabilities and can be used as the target system for ETL pipelines.
Best Practices for Building Robust ETL Pipelines
Building robust and reliable ETL pipelines requires careful planning and execution. Here are some best practices to follow:
- Understand Business Requirements: Clearly define the business requirements and objectives of the ETL pipeline.
- Design a Scalable Architecture: Design the ETL pipeline to handle increasing data volumes and complexity.
- Implement Data Quality Checks: Implement data quality checks at each stage of the ETL pipeline.
- Automate ETL Processes: Automate ETL processes to reduce manual effort and improve efficiency.
- Monitor ETL Performance: Monitor ETL performance and identify bottlenecks.
- Implement Error Handling: Implement robust error handling mechanisms to handle data loading failures.
- Document ETL Processes: Document ETL processes thoroughly to ensure maintainability and reproducibility.
- Use Version Control: Use version control to track changes to ETL code and configurations.
- Test ETL Pipelines Thoroughly: Test ETL pipelines thoroughly to ensure accuracy and reliability.
Challenges in Building and Maintaining ETL Pipelines
Building and maintaining ETL pipelines can be challenging, particularly for large and complex datasets. Some common challenges include:
- Data Volume and Velocity: Handling large volumes of data and high-velocity data streams.
- Data Complexity: Dealing with complex data structures and transformations.
- Data Quality Issues: Addressing data quality issues such as inconsistencies, errors, and duplicates.
- Performance Optimization: Optimizing ETL performance for large datasets and complex transformations.
- Scalability and Reliability: Ensuring the scalability and reliability of ETL pipelines.
- Data Security and Compliance: Protecting sensitive data and ensuring compliance with regulatory requirements.
- Maintaining Data Lineage: Tracking the origin and transformations applied to the data.
- Keeping Up with Evolving Technologies: Staying up-to-date with the latest ETL tools and technologies.
FAQ about ETL Pipelines
Q: What is the difference between ETL and ELT?
A: In ETL, data is extracted, transformed, and then loaded into the target system. In ELT, data is extracted and loaded into the target system before being transformed. ELT leverages the processing power of the target system for transformations, making it suitable for large datasets and cloud-based data warehouses.
Q: How do I choose the right ETL tool?
A: The choice of ETL tool depends on various factors, including the size and complexity of your data, your budget, and your technical expertise. Consider your specific requirements and evaluate different tools based on their features, performance, scalability, and cost.
Q: How can I improve the performance of my ETL pipeline?
A: You can improve ETL performance by optimizing data extraction, transformation, and loading processes. Use efficient data extraction methods, optimize transformation logic, and tune the target system for optimal loading performance. Consider using parallel processing and distributed computing techniques to handle large datasets.
Q: How do I ensure data quality in my ETL pipeline?
A: Implement data quality checks at each stage of the ETL pipeline. Define data quality rules, validate data against these rules, and cleanse and standardize data to ensure accuracy and consistency.
Q: What is data lineage and why is it important?
A: Data lineage is the process of tracking the origin and transformations applied to data as it moves through the ETL pipeline. It is important for understanding the data’s history, identifying potential data quality issues, and ensuring compliance with regulatory requirements.
Conclusion
ETL pipelines are essential for organizations looking to unlock the value of their data. By extracting, transforming, and loading data from various sources into a unified repository, ETL enables business intelligence, improves data quality, and supports data-driven decision-making. Building robust ETL pipelines requires careful planning, execution, and ongoing maintenance. By following best practices and leveraging the right tools and technologies, organizations can create ETL pipelines that are scalable, reliable, and capable of delivering valuable insights from their data. As data continues to grow in volume and complexity, the importance of ETL will only continue to increase, making it a critical skill for data professionals.

Leave a Reply