P1]
In the age of big data, where terabytes of information flow constantly, efficient data processing is paramount. While real-time processing grabs headlines with its immediate responsiveness, batch processing quietly and reliably handles massive datasets in the background, forming the backbone of many crucial operations. This article delves into the world of batch processing, exploring its definition, benefits, limitations, use cases, and best practices.
What is Batch Processing?
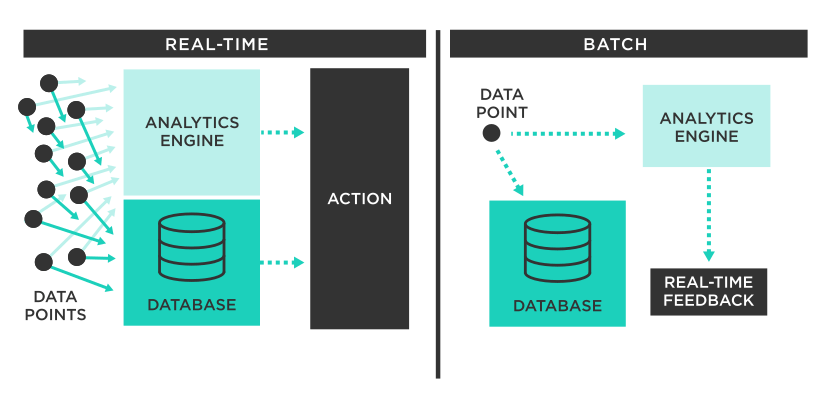
Batch processing is a method of processing large volumes of data in groups or "batches" over a period of time, typically without requiring real-time interaction. Instead of processing each piece of data individually as it arrives (as in real-time processing), batch processing accumulates data over a predefined period or until a certain threshold is reached. The accumulated data is then processed as a single unit, often during off-peak hours when system resources are less strained.
Think of it like this: imagine you’re sorting mail. Real-time processing would be like immediately opening and dealing with each letter as it arrives. Batch processing is like collecting all the mail for the day and then sorting it all at once in the evening.
Key Characteristics of Batch Processing:
- Large Data Volumes: Batch processing is primarily designed for handling large datasets that would be inefficient or impractical to process individually.
- Scheduled Execution: Batch jobs are typically scheduled to run at specific times, often during off-peak hours, to minimize impact on interactive systems.
- No User Interaction: Batch processing typically requires minimal or no user intervention once the job is initiated.
- Sequential Processing: Data within a batch is often processed sequentially, following a predefined set of rules or algorithms.
- Offline Processing: Batch processing typically occurs offline, meaning it doesn’t require immediate results or responses.
Benefits of Batch Processing:
Batch processing offers a range of advantages, making it a valuable tool in various industries:
- Efficiency: By processing data in bulk, batch processing optimizes resource utilization and reduces overhead compared to processing data individually. This is particularly beneficial for resource-intensive operations like data warehousing and analytics.
- Cost-Effectiveness: Processing data during off-peak hours allows organizations to leverage existing infrastructure more effectively, potentially reducing costs associated with dedicated servers or cloud resources.
- Scalability: Batch processing systems can be designed to handle large and growing datasets by scaling resources as needed. This allows organizations to adapt to changing data volumes without significant disruption.
- Automation: Batch jobs can be automated, eliminating the need for manual intervention and freeing up human resources for other tasks.
- Reliability: Batch processing systems are often designed with built-in error handling and recovery mechanisms to ensure data integrity and job completion.
- Suitability for Complex Tasks: Batch processing is well-suited for complex tasks that require significant processing power, such as data transformation, cleansing, and analysis.
- Reduced System Load: By processing data during off-peak hours, batch processing reduces the load on interactive systems, ensuring optimal performance for users.


Limitations of Batch Processing:
Despite its advantages, batch processing also has limitations:
- Latency: Batch processing introduces latency, as data is not processed immediately. This can be a drawback for applications that require real-time or near-real-time responses.
- Complexity: Designing and implementing batch processing systems can be complex, requiring careful planning and consideration of factors such as data partitioning, error handling, and job scheduling.
- Resource Intensive: While efficient in terms of resource utilization over time, batch jobs can be resource-intensive during execution, potentially impacting other systems running concurrently.
- Difficult to Debug: Debugging batch jobs can be challenging, especially when dealing with large datasets and complex processing logic.
- Lack of Interactivity: Batch processing is inherently non-interactive, making it unsuitable for applications that require user input or feedback during processing.
Use Cases of Batch Processing:
Batch processing finds applications across diverse industries, including:
- Financial Services: Processing transactions, generating statements, calculating interest, and performing fraud detection.
- Healthcare: Analyzing patient records, processing insurance claims, and generating reports for regulatory compliance.
- Retail: Analyzing sales data, managing inventory, and generating personalized marketing campaigns.
- Manufacturing: Monitoring production processes, optimizing supply chains, and performing quality control checks.
- Telecommunications: Processing call records, generating billing statements, and analyzing network traffic.
- Data Warehousing and Business Intelligence: Extracting, transforming, and loading (ETL) data from various sources into a data warehouse for analysis and reporting.
- Payroll Processing: Calculating employee salaries, deductions, and taxes.
- Image and Video Processing: Converting file formats, applying filters, and generating thumbnails.
- Scientific Computing: Simulating complex systems, analyzing experimental data, and running statistical models.
- Log Analysis: Parsing and analyzing log files to identify security threats, performance bottlenecks, and other anomalies.
Best Practices for Batch Processing:
To ensure the effectiveness and efficiency of batch processing systems, consider these best practices:
- Careful Planning: Define clear objectives, identify data sources, and design the processing logic before implementation.
- Data Partitioning: Divide large datasets into smaller partitions to enable parallel processing and improve performance.
- Error Handling: Implement robust error handling mechanisms to detect and recover from errors during processing.
- Job Scheduling: Use a reliable job scheduler to manage batch jobs and ensure they run at the appropriate times.
- Monitoring and Logging: Monitor batch job execution and log relevant information for debugging and performance analysis.
- Resource Management: Optimize resource allocation to minimize impact on other systems and ensure efficient utilization.
- Security: Implement security measures to protect sensitive data and prevent unauthorized access.
- Testing and Validation: Thoroughly test and validate batch processing systems to ensure data integrity and accuracy.
- Data Cleansing: Implement data cleansing procedures to remove inconsistencies, errors, and duplicates from the data.
- Performance Optimization: Continuously monitor and optimize batch processing performance by identifying and addressing bottlenecks.
Technologies Used in Batch Processing:
Several technologies are commonly used in batch processing systems:
- Apache Hadoop: A distributed processing framework for handling large datasets.
- Apache Spark: A fast and general-purpose cluster computing system for big data processing.
- Apache Kafka: A distributed streaming platform for building real-time data pipelines and streaming applications.
- AWS Batch: A fully managed batch processing service in the Amazon Web Services (AWS) cloud.
- Azure Batch: A cloud-scale job scheduling and compute management service in the Microsoft Azure cloud.
- Google Cloud Dataflow: A fully managed, unified stream and batch data processing service in the Google Cloud Platform (GCP).
- SQL Databases: Traditional relational databases can be used for batch processing, especially for smaller datasets.
- Scripting Languages: Languages like Python, Perl, and Shell scripting are often used to automate batch processing tasks.
The Future of Batch Processing:
While real-time processing is gaining prominence, batch processing remains a critical component of many data processing workflows. The future of batch processing will likely involve:
- Integration with Real-Time Processing: Combining batch and real-time processing to create hybrid systems that leverage the strengths of both approaches.
- Cloud-Based Batch Processing: Increasing adoption of cloud-based batch processing services for scalability, cost-effectiveness, and ease of management.
- Automation and Orchestration: Greater automation and orchestration of batch processing workflows to improve efficiency and reduce manual intervention.
- Advanced Analytics: Integrating batch processing with advanced analytics techniques such as machine learning to extract deeper insights from data.
FAQ about Batch Processing:
Q: When should I use batch processing instead of real-time processing?
A: Use batch processing when:
- You need to process large volumes of data.
- Immediate results are not required.
- You want to optimize resource utilization.
- You need to perform complex data transformations.
Q: What are the key differences between batch processing and real-time processing?
A: The main differences are:
- Data Volume: Batch processing handles large volumes, while real-time processing handles smaller volumes.
- Latency: Batch processing has high latency, while real-time processing has low latency.
- Resource Utilization: Batch processing optimizes resource utilization over time, while real-time processing requires dedicated resources.
- Interactivity: Batch processing is non-interactive, while real-time processing is interactive.
Q: How do I choose the right technology for batch processing?
A: Consider factors such as:
- Data volume and velocity.
- Processing complexity.
- Scalability requirements.
- Budget constraints.
- Existing infrastructure.
Q: What are some common challenges in batch processing?
A: Common challenges include:
- Handling large datasets.
- Error handling and recovery.
- Job scheduling and management.
- Performance optimization.
- Data security.
Q: How can I improve the performance of my batch processing jobs?
A: Consider these strategies:
- Data partitioning.
- Parallel processing.
- Resource optimization.
- Code optimization.
- Data cleansing.
Conclusion:
Batch processing remains a vital technique for handling large datasets efficiently and reliably. While real-time processing is essential for applications requiring immediate responses, batch processing continues to play a crucial role in data warehousing, analytics, and other areas where processing large volumes of data is paramount. By understanding its benefits, limitations, and best practices, organizations can leverage batch processing to gain valuable insights from their data and optimize their operations. As technology evolves, batch processing will continue to adapt and integrate with other data processing paradigms, ensuring its relevance in the ever-changing landscape of big data.

Leave a Reply