P1]
In today’s data-driven world, the ability to extract, transform, and load (ETL) data efficiently and reliably is paramount. This is where data pipelines come into play. A data pipeline is a series of interconnected steps designed to move data from its source to a destination, often a data warehouse or data lake, where it can be analyzed and used to generate insights. Understanding data pipelines, their components, and best practices is crucial for any organization seeking to leverage the power of its data.
This article will delve into the intricacies of data pipelines, covering their definition, core components, architecture, common challenges, best practices, and future trends. Whether you’re a data engineer, data scientist, or business analyst, this guide will provide you with a comprehensive understanding of this critical data infrastructure component.
What is a Data Pipeline?
At its core, a data pipeline is a set of processes that move data from one or more source systems to one or more destination systems. Think of it as an assembly line for data. Just as a physical assembly line transforms raw materials into finished products, a data pipeline transforms raw data into valuable information.
The primary purpose of a data pipeline is to automate the flow of data, ensuring that it is:
- Accessible: Data is readily available to users who need it.
- Clean: Data is accurate, consistent, and free of errors.
- Transformed: Data is converted into a format suitable for analysis.
- Reliable: Data is delivered consistently and on time.
- Secure: Data is protected from unauthorized access.

Key Components of a Data Pipeline:
A typical data pipeline comprises several key components, each playing a crucial role in the overall process:
Data Sources: These are the origins of the data. They can be internal or external and come in various formats. Common data sources include:
- Databases: Relational databases (e.g., MySQL, PostgreSQL, Oracle) and NoSQL databases (e.g., MongoDB, Cassandra).
- Applications: APIs, web servers, and other applications that generate data.
- Files: CSV, JSON, XML, and other file formats.
- Sensors: IoT devices and other sensors that collect data.
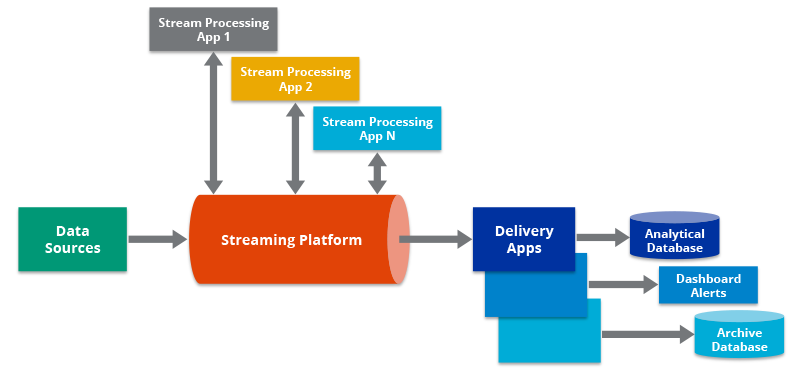
- Streaming Platforms: Kafka, Apache Pulsar, and other platforms that handle real-time data streams.
- Cloud Storage: Amazon S3, Google Cloud Storage, and Azure Blob Storage.

Data Ingestion: This is the process of extracting data from the source systems. It involves connecting to the data sources, authenticating, and retrieving the data. Data ingestion tools and techniques include:
- Batch Ingestion: Extracting data in large batches at regular intervals. Suitable for data sources that are not constantly updated.
- Real-time Ingestion: Extracting data as it is generated. Suitable for streaming data sources and applications that require immediate access to data.
- Change Data Capture (CDC): Identifying and capturing changes made to data in a database. This allows for incremental updates to the destination system, reducing the load on the source system.
Data Transformation: This is the process of cleaning, transforming, and enriching the data. It involves applying various transformations to the data to make it suitable for analysis. Common data transformation tasks include:
- Data Cleaning: Removing errors, inconsistencies, and duplicates from the data.
- Data Validation: Ensuring that the data meets certain quality standards.
- Data Enrichment: Adding additional information to the data from external sources.
- Data Aggregation: Summarizing data to create higher-level insights.
- Data Filtering: Selecting specific data based on certain criteria.
- Data Standardization: Converting data to a consistent format.
Data Storage: This is the destination where the transformed data is stored. Common data storage solutions include:
- Data Warehouses: Centralized repositories of structured data designed for analytical reporting and decision support. Examples include Snowflake, Amazon Redshift, and Google BigQuery.
- Data Lakes: Centralized repositories of both structured and unstructured data. Data lakes are often used for data discovery, exploration, and machine learning. Examples include Amazon S3, Azure Data Lake Storage, and Google Cloud Storage.
- Databases: Relational and NoSQL databases can also be used as data storage solutions, particularly for specific use cases.
Data Orchestration: This is the process of coordinating and managing the different components of the data pipeline. It involves scheduling tasks, monitoring progress, and handling errors. Data orchestration tools include:
- Apache Airflow: A popular open-source platform for programmatically authoring, scheduling, and monitoring workflows.
- Prefect: An open-source data workflow orchestration platform that focuses on reliability and observability.
- Dagster: A data orchestrator designed for developing and deploying production-grade data assets.
- Cloud-based Orchestration Services: AWS Step Functions, Google Cloud Composer, and Azure Data Factory.


Data Pipeline Architecture:
The architecture of a data pipeline can vary depending on the specific requirements of the organization. However, there are some common architectural patterns:
- Batch Processing: Data is processed in large batches at regular intervals. This is a simple and efficient approach for data sources that are not constantly updated.
- Real-time Processing: Data is processed as it is generated. This is suitable for streaming data sources and applications that require immediate access to data.
- Lambda Architecture: Combines batch and real-time processing to provide both speed and accuracy. Data is processed in both a batch layer and a speed layer. The batch layer provides accurate results based on historical data, while the speed layer provides near real-time results.
- Kappa Architecture: Simplifies the Lambda Architecture by eliminating the batch layer. All data is processed through a single stream processing pipeline.
Common Challenges in Building Data Pipelines:
Building and maintaining data pipelines can be challenging. Some common challenges include:
- Data Volume: Dealing with large volumes of data can be challenging, requiring scalable infrastructure and efficient data processing techniques.
- Data Variety: Data comes in various formats and from different sources, requiring complex data transformation and integration techniques.
- Data Velocity: Real-time data streams require high-performance data processing and low-latency storage solutions.
- Data Veracity: Ensuring data quality and accuracy can be challenging, requiring robust data validation and cleaning techniques.
- Complexity: Building and managing data pipelines can be complex, requiring specialized skills and tools.
- Scalability: Data pipelines need to be scalable to handle increasing data volumes and changing business requirements.
- Reliability: Data pipelines need to be reliable to ensure that data is delivered consistently and on time.
- Security: Data pipelines need to be secure to protect data from unauthorized access.
Best Practices for Building Data Pipelines:
To overcome the challenges of building data pipelines, it is important to follow best practices:
- Define Clear Requirements: Clearly define the purpose of the data pipeline, the data sources, the data transformations, and the data destination.
- Choose the Right Tools: Select the right tools for each component of the data pipeline based on the specific requirements.
- Automate Everything: Automate all aspects of the data pipeline, including data ingestion, data transformation, data storage, and data orchestration.
- Monitor Performance: Monitor the performance of the data pipeline to identify bottlenecks and optimize performance.
- Implement Error Handling: Implement robust error handling to ensure that errors are detected and handled appropriately.
- Test Thoroughly: Test the data pipeline thoroughly to ensure that it is working correctly.
- Document Everything: Document all aspects of the data pipeline, including the architecture, the components, and the configuration.
- Implement Security Measures: Implement security measures to protect data from unauthorized access.
- Use Version Control: Use version control to track changes to the data pipeline.
- Embrace Infrastructure as Code (IaC): Manage your infrastructure using code to ensure consistency and reproducibility.
Future Trends in Data Pipelines:
The field of data pipelines is constantly evolving. Some future trends include:
- Increased Automation: Increased automation of data pipeline development and management.
- Serverless Architectures: Adoption of serverless architectures for data pipelines.
- AI-Powered Data Pipelines: Use of AI and machine learning to automate data quality checks and data transformation tasks.
- Data Mesh: A decentralized approach to data ownership and governance.
- Data Observability: Increased focus on monitoring and observability of data pipelines.
- Real-time Data Pipelines as Standard: Moving towards real-time processing as the expected norm rather than the exception.
- Low-Code/No-Code Solutions: Democratizing data pipeline creation with easier-to-use tools for non-technical users.
Conclusion:
Data pipelines are the backbone of modern data analysis. They enable organizations to extract, transform, and load data efficiently and reliably, allowing them to gain valuable insights from their data. By understanding the key components, architecture, challenges, and best practices of data pipelines, organizations can build robust and scalable data infrastructure that supports their business goals. As the volume, variety, and velocity of data continue to increase, the importance of data pipelines will only grow. Staying ahead of the curve by embracing new technologies and best practices will be crucial for organizations seeking to leverage the power of their data in the future.
FAQ:
Q1: What is the difference between ETL and ELT?
A: ETL (Extract, Transform, Load) is a traditional approach where data is extracted, transformed, and then loaded into the data warehouse. ELT (Extract, Load, Transform) loads the raw data directly into the data warehouse and then transforms it within the warehouse. ELT is often preferred with modern cloud data warehouses as they offer the processing power to handle transformations.
Q2: What are the benefits of using a data pipeline?
A: Data pipelines offer several benefits, including:
- Improved Data Quality: Data pipelines can help to improve data quality by cleaning, transforming, and validating data.
- Increased Efficiency: Data pipelines can automate the flow of data, reducing the need for manual data processing.
- Better Decision Making: Data pipelines can provide users with access to accurate and timely data, enabling them to make better decisions.
- Scalability: Data pipelines can be scaled to handle increasing data volumes and changing business requirements.
Q3: What are some popular data pipeline tools?
A: Some popular data pipeline tools include:
- Apache Airflow
- Prefect
- Dagster
- Talend
- Informatica PowerCenter
- AWS Glue
- Google Cloud Dataflow
- Azure Data Factory
- Snowflake Snowpipe
Q4: How do I choose the right data pipeline architecture?
A: The right data pipeline architecture depends on the specific requirements of your organization. Consider factors such as the data volume, variety, velocity, and veracity, as well as the performance and scalability requirements.
Q5: How do I ensure the security of my data pipeline?
A: To ensure the security of your data pipeline, implement security measures such as:
- Authentication and Authorization: Control access to data and resources.
- Encryption: Encrypt data in transit and at rest.
- Data Masking: Mask sensitive data to protect it from unauthorized access.
- Auditing: Track all activities in the data pipeline to detect and prevent security breaches.
- Network Security: Secure the network infrastructure to prevent unauthorized access.
Q6: What are some common mistakes to avoid when building data pipelines?
A: Some common mistakes to avoid when building data pipelines include:
- Lack of Planning: Failing to properly plan the data pipeline before starting development.
- Ignoring Data Quality: Neglecting to implement data quality checks and data cleaning processes.
- Insufficient Testing: Not thoroughly testing the data pipeline before deploying it to production.
- Poor Documentation: Failing to document the data pipeline architecture, components, and configuration.
- Ignoring Security: Neglecting to implement security measures to protect data from unauthorized access.
Leave a Reply