P1]
In the realm of data warehousing, where efficient querying and analysis are paramount, the choice of schema plays a critical role. Among the various options, the Snowflake schema stands out as a powerful and flexible approach that optimizes performance and reduces data redundancy. This article delves deep into the intricacies of the Snowflake schema, exploring its structure, advantages, disadvantages, and applications, providing a comprehensive understanding of this valuable data warehousing technique.
Understanding the Fundamentals: What is a Schema?
Before diving into the specifics of the Snowflake schema, it’s essential to understand the concept of a schema itself. In the context of databases and data warehousing, a schema defines the structure and organization of the data. It specifies the tables, columns, data types, relationships between tables, and constraints that govern the data’s integrity. Essentially, a schema provides a blueprint for how data is stored and accessed.
The Snowflake Schema: A Star Schema with a Twist
The Snowflake schema is a variation of the star schema, a widely used data warehouse design. The star schema consists of a central fact table surrounded by dimension tables. The fact table contains the core business data, such as sales transactions, website visits, or sensor readings. Dimension tables contain descriptive attributes that provide context to the fact table data. Examples of dimensions include customer, product, location, and time.
While the Snowflake schema shares the same core structure as the star schema, the key difference lies in the normalization of the dimension tables. In a star schema, dimension tables are typically denormalized, meaning that they may contain redundant data to improve query performance. In contrast, the Snowflake schema normalizes dimension tables, breaking them down into smaller, related tables.
Anatomy of a Snowflake Schema: Fact Tables and Normalized Dimensions
Let’s break down the components of a Snowflake schema:

Fact Table: This central table contains the core business data, usually numerical measures (facts) and foreign keys referencing dimension tables. The fact table is the focal point for analysis and reporting. For example, a fact table might contain sales amount, quantity sold, and foreign keys referencing customer, product, location, and time dimensions.
Dimension Tables: These tables contain descriptive attributes that provide context to the facts. In a Snowflake schema, dimension tables are normalized, meaning that they are broken down into smaller, related tables. This normalization reduces data redundancy and improves data integrity. For example, a customer dimension table might be further divided into customer, address, and demographic tables.
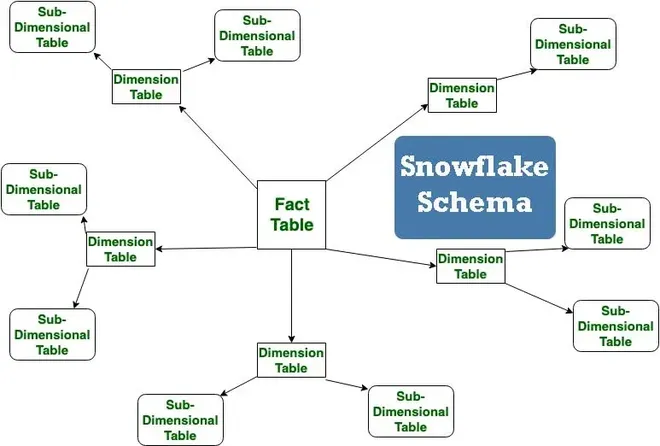

Illustrative Example: Sales Data Warehouse
Consider a sales data warehouse. In a star schema, you might have a single Customer dimension table containing all customer information:
Customer(CustomerID, Name, Address, City, State, ZipCode, Age, Gender)

In a Snowflake schema, this Customer dimension table could be normalized into three tables:
Customer(CustomerID, Name, AddressID, DemographicID)Address(AddressID, Address, City, State, ZipCode)Demographic(DemographicID, Age, Gender)
The Customer table now only contains the most frequently accessed customer attributes and foreign keys referencing the Address and Demographic tables. This normalization reduces data redundancy and makes it easier to update address or demographic information without affecting the main Customer table.
Advantages of the Snowflake Schema
The Snowflake schema offers several advantages over the star schema and other data warehousing designs:
Reduced Data Redundancy: Normalizing dimension tables minimizes data duplication, leading to more efficient storage utilization and reduced data inconsistencies. This is particularly beneficial for large datasets where redundancy can significantly impact storage costs.
Improved Data Integrity: Normalization enforces data integrity by ensuring that each attribute is stored in only one place. This reduces the risk of inconsistencies and simplifies data updates.
Easier Data Maintenance: Normalization simplifies data maintenance by making it easier to update and modify data. Changes to a specific attribute only need to be made in one location, ensuring consistency across the entire data warehouse.
Support for Complex Relationships: The Snowflake schema can effectively represent complex relationships between dimensions. Normalizing dimension tables allows for a more granular and accurate representation of the data.
Flexibility and Scalability: The Snowflake schema is highly flexible and scalable. It can easily accommodate changes in business requirements and data volumes. Adding new dimensions or attributes is relatively straightforward.
Disadvantages of the Snowflake Schema
Despite its advantages, the Snowflake schema also has some drawbacks:
Increased Query Complexity: Normalization introduces more joins in queries, which can increase query complexity and potentially slow down query performance. Query optimizers can often mitigate this, but it’s a factor to consider.
Higher Development and Maintenance Costs: Designing and implementing a Snowflake schema can be more complex and time-consuming than designing a star schema. Maintaining the normalized dimension tables also requires more effort.
Potential Performance Overhead: The increased number of joins can introduce performance overhead, especially for complex queries. Careful query optimization and indexing are crucial to mitigate this issue.
When to Use a Snowflake Schema
The Snowflake schema is a suitable choice for data warehousing projects with the following characteristics:
Large Datasets: When dealing with large datasets, the reduction in data redundancy offered by the Snowflake schema can significantly impact storage costs and improve query performance.
Complex Data Relationships: If the data involves complex relationships between dimensions, the Snowflake schema provides a more accurate and flexible representation.
Data Integrity Requirements: When data integrity is paramount, the normalization of dimension tables ensures data consistency and reduces the risk of errors.
Frequent Data Updates: If the data is frequently updated, the Snowflake schema simplifies data maintenance and reduces the risk of inconsistencies.
Availability of Skilled Resources: Designing and implementing a Snowflake schema requires experienced data warehouse professionals.
Alternatives to the Snowflake Schema
While the Snowflake schema is a powerful option, other data warehousing schemas may be more suitable in certain situations:
Star Schema: The star schema is a simpler and more widely used alternative. It is suitable for smaller datasets with simpler data relationships.
Galaxy Schema (Fact Constellation Schema): The galaxy schema consists of multiple fact tables sharing dimension tables. It is suitable for complex data warehouses with multiple business areas.
Data Vault: The Data Vault is a modeling technique designed for long-term data storage and auditing. It is suitable for large, complex data warehouses with high data volatility.
Implementation Considerations
When implementing a Snowflake schema, consider the following:
Normalization Level: Determine the appropriate level of normalization for dimension tables. Over-normalization can lead to excessive joins and performance overhead, while under-normalization can result in data redundancy and inconsistencies.
Indexing: Properly index the tables to optimize query performance. Focus on indexing foreign key columns and frequently queried columns.
Query Optimization: Optimize queries to minimize the number of joins and improve execution time. Use query optimizers and performance monitoring tools to identify and address performance bottlenecks.
Data Governance: Establish clear data governance policies to ensure data quality, consistency, and security.
FAQ about Snowflake Schema
Q: What is the main difference between a star schema and a Snowflake schema?
A: The main difference is the normalization of dimension tables. In a star schema, dimension tables are typically denormalized, while in a Snowflake schema, they are normalized into smaller, related tables.
Q: Is a Snowflake schema always better than a star schema?
A: No, it depends on the specific requirements of the data warehouse. The star schema is simpler and can be more efficient for smaller datasets with simpler data relationships. The Snowflake schema is better suited for larger datasets with complex relationships and high data integrity requirements.
Q: What are the performance implications of using a Snowflake schema?
A: The normalization in a Snowflake schema can lead to more joins in queries, potentially impacting performance. However, proper indexing, query optimization, and powerful database systems can mitigate this issue.
Q: How do I choose the right level of normalization for my Snowflake schema?
A: The right level of normalization depends on the trade-off between data redundancy and query performance. Aim for a level that minimizes data redundancy without introducing excessive joins that negatively impact performance.
Q: Is the Snowflake schema related to the Snowflake data warehouse platform?
A: While the term "Snowflake schema" refers to a specific data warehousing design, the Snowflake data warehouse platform is a cloud-based data warehousing service. The Snowflake platform can support various schema designs, including the Snowflake schema.
Conclusion: A Powerful Tool for Data Warehousing
The Snowflake schema is a powerful and flexible data warehousing technique that offers significant advantages in terms of data redundancy, data integrity, and data maintenance. While it can introduce complexity and potential performance overhead, these drawbacks can be mitigated through careful design, indexing, and query optimization. By understanding the intricacies of the Snowflake schema and its suitability for different scenarios, data warehouse professionals can leverage its strengths to build efficient and robust data warehousing solutions that meet the evolving needs of their organizations. When faced with large datasets, complex relationships, and stringent data integrity requirements, the Snowflake schema provides a solid foundation for building a successful data warehouse.

Leave a Reply