P1]
In today’s data-driven world, organizations are constantly bombarded with information from various sources. This data, often unstructured and disparate, holds immense potential for driving strategic decision-making, improving operational efficiency, and gaining a competitive edge. However, raw data is rarely in a usable format. This is where ETL (Extract, Transform, Load) comes into play, acting as the crucial pipeline that converts raw data into valuable insights.
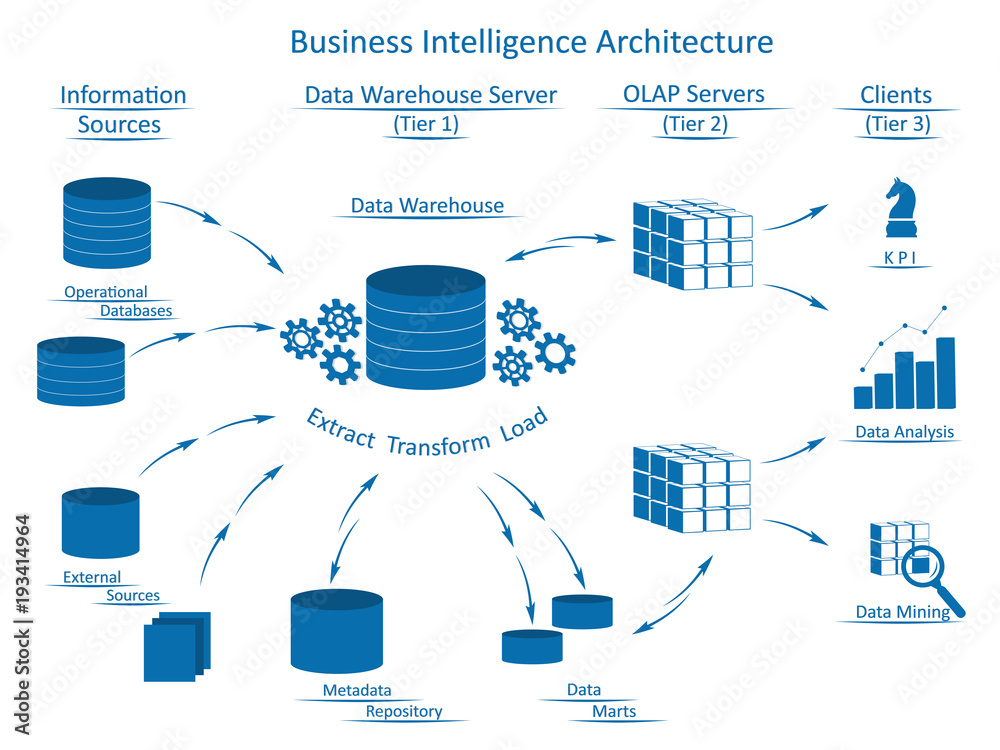
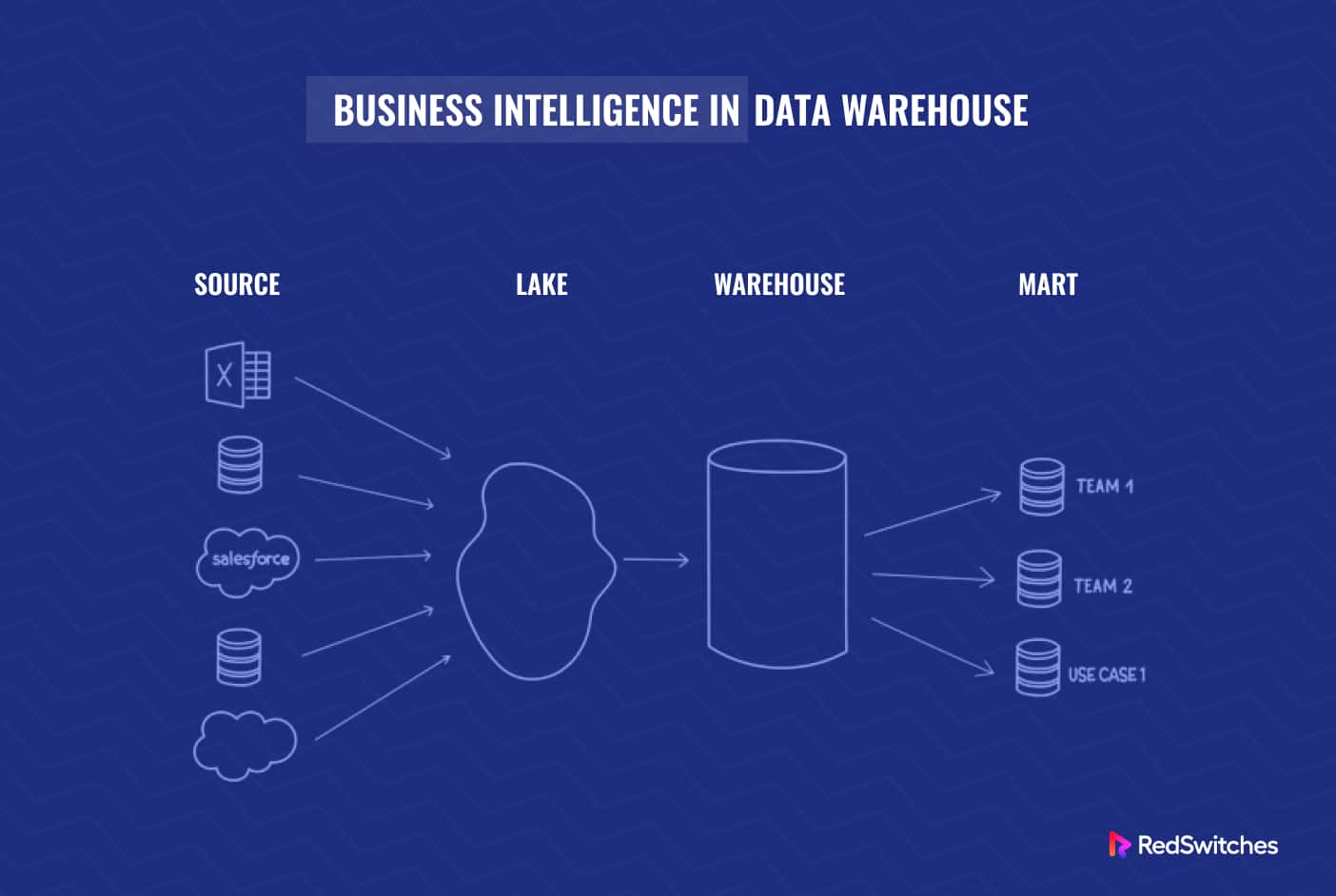
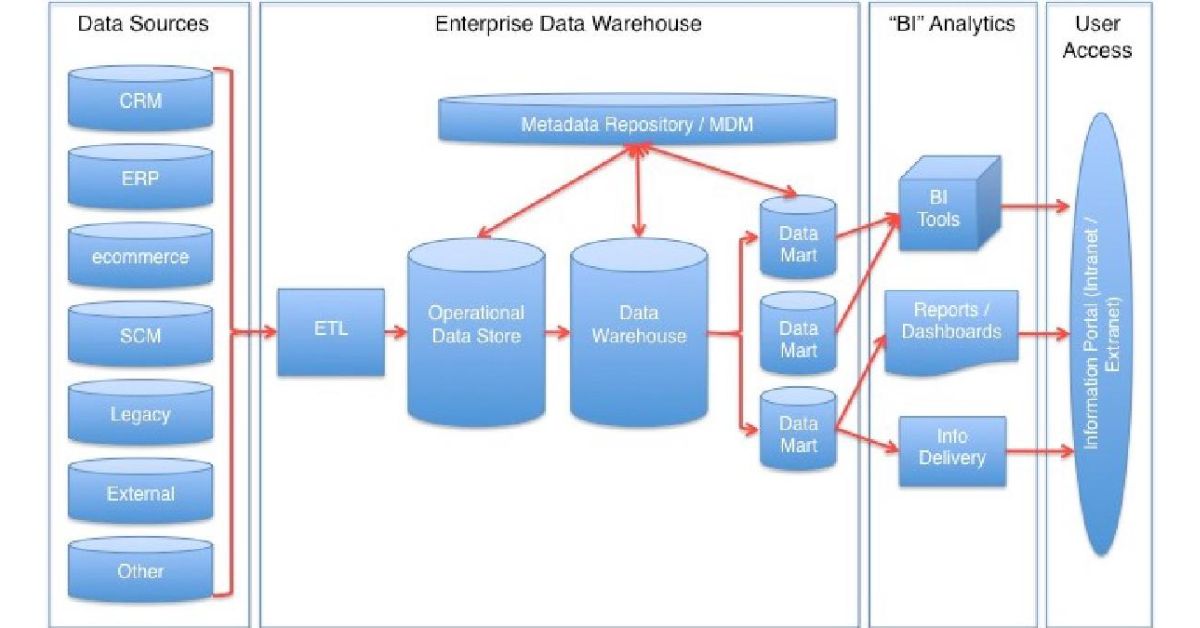
ETL is a three-stage process used to consolidate data from multiple sources into a centralized data warehouse or data lake. It involves extracting data from various sources, transforming it into a consistent and usable format, and loading it into the target system. Think of it as a meticulous cleaning, organizing, and packaging process for raw data, making it ready for analysis and reporting.
The Three Pillars of ETL: Extract, Transform, Load
Let’s delve into each stage of the ETL process in detail:
1. Extract:
The extraction stage is the foundation of the entire ETL process. It involves identifying and retrieving data from various source systems. These sources can be incredibly diverse, including:
- Relational Databases: Oracle, MySQL, PostgreSQL, SQL Server
- NoSQL Databases: MongoDB, Cassandra, Couchbase
- Flat Files: CSV, TXT, Excel
- Cloud Storage: Amazon S3, Azure Blob Storage, Google Cloud Storage
- APIs: Web services, REST APIs, SOAP APIs
- Legacy Systems: Mainframes, outdated databases
The extraction process must be carefully planned to ensure data integrity and minimize disruption to the source systems. Key considerations during the extraction phase include:
- Data Selection: Determining which data is relevant for the target system.
- Extraction Frequency: Defining how often data should be extracted (e.g., daily, hourly, real-time).
- Extraction Method: Choosing the appropriate method for extracting data based on the source system and data volume (e.g., full extraction, incremental extraction).
- Error Handling: Implementing mechanisms to handle errors during extraction and prevent data loss.
- Data Validation: Performing initial data quality checks to identify and address potential issues early on.
Types of Extraction:
- Full Extraction: This involves extracting all the data from the source system. While simple to implement, it can be time-consuming and resource-intensive, especially for large datasets.
- Incremental Extraction: This extracts only the data that has changed since the last extraction. This approach is more efficient for large datasets and frequent updates. It requires mechanisms to track data changes, such as timestamps or change data capture (CDC).
- Change Data Capture (CDC): A sophisticated technique that identifies and captures data changes in real-time or near real-time. This ensures that the target system is always up-to-date with the latest information.
2. Transform:
The transformation stage is where the raw data is cleaned, processed, and converted into a format suitable for the target system. This is often the most complex and time-consuming stage of the ETL process, requiring a deep understanding of both the source data and the target system requirements.
Common transformation tasks include:
- Data Cleaning: Removing inconsistencies, errors, and duplicates from the data. This might involve correcting typos, standardizing date formats, or filling in missing values.
- Data Standardization: Ensuring that data is consistent across different sources. This might involve converting units of measurement, standardizing address formats, or mapping codes to a common set of values.
- Data Enrichment: Adding additional information to the data to improve its usefulness. This might involve looking up customer information, calculating derived values, or geocoding addresses.
- Data Aggregation: Summarizing data to create higher-level insights. This might involve calculating totals, averages, or counts.
- Data Filtering: Removing irrelevant data from the dataset.
- Data Sorting: Ordering data based on specific criteria.
- Data Joining: Combining data from multiple sources based on common keys.
- Data Splitting: Dividing data into smaller subsets based on specific criteria.
- Data Type Conversion: Converting data from one data type to another (e.g., string to integer).
Transformation Techniques:
- Lookup Tables: Using predefined tables to map values from one system to another.
- Conditional Statements: Using IF-THEN-ELSE logic to transform data based on specific conditions.
- String Manipulation: Using functions to manipulate text strings, such as extracting substrings, replacing characters, or converting to uppercase or lowercase.
- Mathematical Functions: Using mathematical functions to perform calculations on numerical data.
3. Load:
The loading stage involves writing the transformed data into the target system, which is typically a data warehouse or data lake. This stage must be performed efficiently and reliably to ensure data integrity and minimize downtime.
Key considerations during the loading phase include:
- Loading Method: Choosing the appropriate method for loading data based on the target system and data volume (e.g., full load, incremental load).
- Data Validation: Performing final data quality checks to ensure that the data has been loaded correctly.
- Error Handling: Implementing mechanisms to handle errors during loading and prevent data loss.
- Performance Optimization: Tuning the loading process to maximize performance and minimize loading time.
- Data Integrity: Ensuring that the data is consistent and accurate after loading.
Types of Loading:
- Full Load: This involves replacing all the existing data in the target system with the transformed data. This is typically done when the target system is first populated or when a significant amount of data has changed.
- Incremental Load: This involves adding or updating data in the target system based on the changes that have occurred since the last load. This is a more efficient approach for large datasets and frequent updates.
ETL Tools and Technologies:
Numerous ETL tools and technologies are available, ranging from open-source solutions to commercial platforms. Some popular options include:
- Informatica PowerCenter: A leading commercial ETL platform with a wide range of features and capabilities.
- IBM DataStage: Another popular commercial ETL platform with strong integration with IBM’s data warehousing solutions.
- Talend Open Studio: An open-source ETL tool with a user-friendly interface and a wide range of connectors.
- Apache NiFi: An open-source data flow management system that can be used for ETL.
- Apache Spark: A powerful distributed processing engine that can be used for ETL and other data processing tasks.
- AWS Glue: A fully managed ETL service from Amazon Web Services.
- Azure Data Factory: A fully managed ETL service from Microsoft Azure.
- Google Cloud Dataflow: A fully managed ETL service from Google Cloud Platform.
- Python with Libraries like Pandas and Dask: A flexible and powerful option for custom ETL pipelines, especially useful for data scientists and those comfortable with coding.
The choice of ETL tool depends on factors such as the size and complexity of the data, the required performance, the budget, and the technical expertise of the team.
Benefits of ETL:
- Improved Data Quality: ETL processes clean and standardize data, ensuring that it is accurate and consistent.
- Increased Data Accessibility: ETL consolidates data from multiple sources into a centralized data warehouse or data lake, making it easier for users to access and analyze.
- Enhanced Business Intelligence: ETL provides a foundation for business intelligence by providing clean, consistent, and accessible data.
- Better Decision-Making: ETL empowers organizations to make better decisions by providing them with accurate and timely insights.
- Improved Operational Efficiency: ETL automates the data integration process, freeing up resources and improving operational efficiency.
- Historical Data Analysis: ETL allows organizations to analyze historical data to identify trends and patterns.
- Regulatory Compliance: ETL can help organizations comply with regulatory requirements by ensuring that data is accurate and complete.
Challenges of ETL:
- Complexity: ETL processes can be complex, especially when dealing with large datasets and diverse data sources.
- Time-Consuming: ETL development and implementation can be time-consuming, requiring significant effort from developers and data engineers.
- Cost: ETL tools and infrastructure can be expensive, especially for large organizations.
- Data Quality Issues: Poor data quality can lead to inaccurate insights and flawed decision-making.
- Scalability: ETL systems must be scalable to handle growing data volumes and changing business requirements.
- Security: ETL processes must be secure to protect sensitive data from unauthorized access.
FAQ about ETL:
Q: What is the difference between ETL and ELT?
A: ETL (Extract, Transform, Load) transforms the data before loading it into the target system, while ELT (Extract, Load, Transform) loads the raw data into the target system first and then transforms it. ELT is often used with modern data warehouses that have the processing power to handle transformations.
Q: When should I use ETL vs. ELT?
A: Use ETL when your target system has limited processing power or when you need to perform complex transformations before loading the data. Use ELT when your target system has sufficient processing power and you want to take advantage of its scalability and parallel processing capabilities. Also, ELT is preferred when you want to keep the raw data for audit or compliance purposes.
Q: What is a Data Warehouse?
A: A data warehouse is a centralized repository of integrated data from various sources, designed for analytical reporting and decision-making.
Q: What is a Data Lake?
A: A data lake is a centralized repository that stores data in its raw, unprocessed form. It can store structured, semi-structured, and unstructured data.
Q: What is Change Data Capture (CDC)?
A: Change Data Capture (CDC) is a technique for identifying and capturing data changes in real-time or near real-time. This ensures that the target system is always up-to-date with the latest information.
Q: How do I choose the right ETL tool?
A: Consider factors such as the size and complexity of your data, the required performance, the budget, the technical expertise of your team, and the integration capabilities with your existing systems.
Q: What are some best practices for ETL?
A: Plan your ETL process carefully, design a robust data model, implement thorough data quality checks, monitor the performance of your ETL system, and document your ETL process.
Q: What skills are required for ETL development?
A: Skills in database design, SQL, data modeling, data warehousing, programming (e.g., Python, Java), and experience with ETL tools are essential.
Conclusion:
ETL is a critical process for organizations that want to leverage the power of their data. By extracting, transforming, and loading data from various sources into a centralized data warehouse or data lake, ETL enables organizations to improve data quality, increase data accessibility, enhance business intelligence, and make better decisions. While ETL can be complex and challenging, the benefits it provides far outweigh the costs. As data volumes continue to grow and become more diverse, ETL will remain a vital component of any data-driven organization’s strategy. Choosing the right tools, implementing best practices, and investing in the necessary skills are crucial for successful ETL implementation and achieving maximum value from your data.

Leave a Reply